Trong kỷ nguyên số ngày nay, nhu cầu lưu trữ dữ liệu ngày càng tăng cao, đặc biệt là đối với các doanh nghiệp và tổ chức. Tuy nhiên, việc lưu trữ một lượng lớn dữ liệu đồng nghĩa với việc tốn kém chi phí và lãng phí không gian lưu trữ. Do đó, công nghệ chống trùng lặp dữ liệu đóng vai trò vô cùng quan trọng trong việc tối ưu hóa hiệu quả lưu trữ và tiết kiệm chi phí cho người dùng.
Synology, thương hiệu NAS uy tín hàng đầu, đã tích hợp công nghệ chống trùng lặp dữ liệu tiên tiến vào các thiết bị NAS của mình, mang đến cho người dùng giải pháp lưu trữ thông minh và tiết kiệm. Hãy cùng Thietbinas.com tìm hiểu về công nghệ chống trùng lặp dữ liệu trên NAS Synology cùng với cách thức hoạt động, lợi ích và những ứng dụng thực tế nhé.

Trùng lặp dữ liệu là gì?
Trùng lặp dữ liệu (Data duplication) xảy ra khi cùng một thông tin được lưu trữ nhiều lần trong một hệ thống hoặc trên nhiều hệ thống khác nhau. Điều này có thể dẫn đến một số vấn đề như:
- Lãng phí dung lượng lưu trữ: Việc lưu trữ nhiều bản sao của cùng một dữ liệu sẽ tốn kém chi phí và chiếm dụng không gian lưu trữ không cần thiết.
- Giảm hiệu quả truy xuất dữ liệu: Khi cần truy xuất dữ liệu, hệ thống sẽ phải tìm kiếm qua nhiều bản sao, dẫn đến tốn thời gian và làm giảm hiệu quả hoạt động.
- Gây khó khăn cho việc quản lý dữ liệu: Việc quản lý nhiều bản sao của cùng một dữ liệu sẽ trở nên phức tạp và tốn nhiều thời gian, đồng thời cũng tiềm ẩn nguy cơ sai sót trong việc cập nhật dữ liệu.
- Tăng nguy cơ mất dữ liệu: Nếu một bản sao dữ liệu bị hỏng hoặc bị xóa, có thể dẫn đến việc mất dữ liệu hoàn toàn.
Giới thiệu về công nghệ chống trùng lặp dữ liệu
Chống trùng lặp dữ liệu là công nghệ tiên tiến giúp giảm thiểu dung lượng lưu trữ cần thiết cho dữ liệu, mang lại lợi ích to lớn cho các tổ chức trong việc quản lý dữ liệu hiệu quả.
Công nghệ này hoạt động bằng cách xác định và loại bỏ dữ liệu trùng lặp khỏi nguồn dữ liệu, bao gồm tệp, khối hoặc byte. Nhờ đó, doanh nghiệp có thể tiết kiệm chi phí lưu trữ, tối ưu hóa hiệu suất và đảm bảo an toàn cho dữ liệu.
Quy trình chống trùng lặp dữ liệu diễn ra như sau:
- Tạo dấu vân tay: Mỗi phần dữ liệu được tạo một mã định danh riêng biệt, gọi là dấu vân tay, để xác định nguồn gốc của nó.
- So sánh dấu vân tay: Khi dữ liệu mới được thêm vào, dấu vân tay của nó sẽ được so sánh với dấu vân tay của tất cả dữ liệu hiện có.
- Loại bỏ dữ liệu trùng lặp: Nếu dấu vân tay trùng khớp, dữ liệu mới được coi là trùng lặp và sẽ bị xóa khỏi nguồn dữ liệu. Thay thế bằng một con trỏ dẫn đến bản sao gốc.

Các phương pháp chống trùng lặp dữ liệu
Để đảm bảo tính chính xác và hiệu quả trong việc lưu trữ và quản lý dữ liệu, việc chống trùng lặp dữ liệu đóng vai trò vô cùng quan trọng. Ba phương pháp chống trùng lặp chính được sử dụng phổ biến hiện nay bao gồm:
- Chống trùng lặp nội tuyến: Xảy ra trong quá trình ghi dữ liệu vào nguồn. Đây là phương pháp hiệu quả nhất, giúp loại bỏ trùng lặp ngay từ đầu, tuy nhiên đòi hỏi nguồn lực xử lý mạnh mẽ.
- Chống trùng lặp sau quá trình: Diễn ra sau khi đã ghi toàn bộ dữ liệu vào nguồn. Phương pháp này ít hiệu quả hơn so với chống trùng lặp nội tuyến, nhưng lại tiết kiệm chi phí về nguồn lực xử lý.
- Chống trùng lặp nguồn: Thực hiện trước khi truyền dữ liệu từ vị trí này sang vị trí khác. Mặc dù hiệu quả thấp nhất, nhưng phương pháp này giúp giảm thiểu lượng dữ liệu cần truyền tải, tiết kiệm băng thông và thời gian.
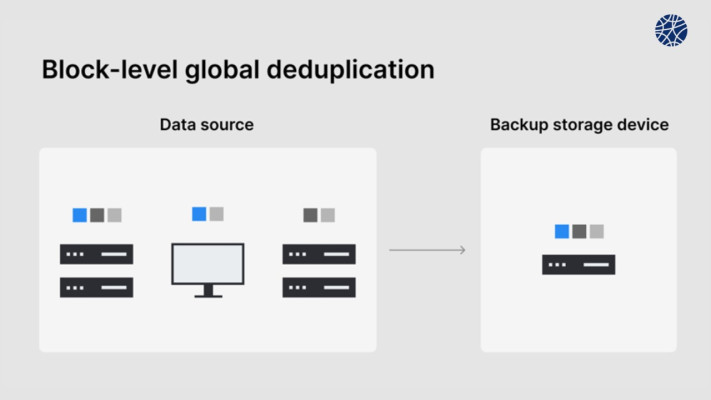
Các trường hợp sử dụng chống trùng lặp dữ liệu
Bằng cách giảm bớt gánh nặng dữ liệu dư thừa, tính năng chống trùng lặp dữ liệu có thể hỗ trợ doanh nghiệp giảm chi phí lưu trữ và tối ưu hóa không gian trống trên ổ đĩa. Các phần trùng lặp của tập dữ liệu của ổ đĩa chỉ được lưu trữ một lần, với tùy chọn thu gọn chúng để giảm hơn nữa yêu cầu lưu trữ. Chống trùng lặp dữ liệu làm giảm sự lặp lại và sao chép trong khi vẫn đảm bảo tính toàn vẹn của dữ liệu. Các công ty có thể sử dụng tính năng chống trùng lặp dữ liệu ở bất cứ nơi nào có liên quan đến việc lưu trữ hoặc sao lưu dữ liệu. Một số trường hợp sử dụng điển hình của việc chống trùng lặp dữ liệu bao gồm:
- Máy chủ tập tin: Đây là những máy chủ tệp đáp ứng nhiều chức năng và có thể lưu trữ bất kỳ chia sẻ tệp/tài liệu nào được mọi người trong nhóm chia sẻ hoặc nằm trong các thư mục cá nhân hoặc liên quan đến công việc của người dùng. Máy chủ tệp có mục đích chung là lựa chọn tuyệt vời để chống trùng lặp dữ liệu vì nhiều người dùng thường có nhiều phiên bản hoặc bản sao của một tài liệu hay tệp.
- Cơ sở hạ tầng máy ảo (VDI): Cơ sở hạ tầng máy ảo (VDI) mang đến dịch vụ máy tính từ xa, cung cấp cho doanh nghiệp phương thức đơn giản để trang bị PC cho nhân viên. Doanh nghiệp có thể ứng dụng công nghệ này cho nhiều mục đích như triển khai ứng dụng, hợp nhất hệ thống và hỗ trợ truy cập từ xa. Việc cài đặt VDI còn là giải pháp chống trùng lặp dữ liệu hiệu quả, do các đĩa cứng ảo cung cấp cho máy tính để bàn từ xa của người dùng gần như giống hệt nhau. Thêm vào đó, tính năng sao lưu dữ liệu còn hỗ trợ cho việc khởi động VDI êm ái, hạn chế tình trạng giật lag khi nhiều người dùng truy cập đồng thời.
- Mục tiêu dự phòng: Bao gồm các ứng dụng sao lưu ảo hóa. Trình quản lý bảo vệ của Microsoft (DPM) và các công cụ sao lưu khác rất lý tưởng cho việc chống trùng lặp dữ liệu do có sự trùng lặp đáng kể giữa các ảnh chụp sao lưu nhanh.
Lợi ích của việc chống trùng lặp dữ liệu
Có nhiều lợi ích khi sử dụng tính năng chống trùng lặp dữ liệu, bao gồm:
- Giảm chi phí lưu trữ: Sao chép dữ liệu có thể giảm đáng kể dung lượng lưu trữ cần thiết cho nguồn dữ liệu. Điều này có thể giúp tiết kiệm chi phí đáng kể, đặc biệt đối với các nguồn dữ liệu lớn.
- Cải thiện hiệu suất: Sao chép dữ liệu có thể cải thiện hiệu suất của nguồn dữ liệu bằng cách giảm lượng dữ liệu cần truy cập. Điều này đặc biệt có lợi cho cơ sở dữ liệu và các ứng dụng khác yêu cầu truy cập thường xuyên vào lượng lớn dữ liệu.
- Cải thiện bảo mật: Tính năng chống trùng lặp dữ liệu có thể cải thiện tính bảo mật của nguồn dữ liệu bằng cách giảm số lượng bản sao của dữ liệu nhạy cảm được lưu trữ. Điều này khiến kẻ tấn công khó truy cập dữ liệu nhạy cảm hơn.
- Phục hồi dữ liệu tốt hơn: Tính năng chống trùng lặp dữ liệu tăng tốc độ phục hồi sao lưu bằng cách loại bỏ dữ liệu dư thừa khỏi danh sách kết hợp. Nó làm giảm thời gian ngừng hoạt động và hỗ trợ duy trì khả năng tồn tại của các chiến lược kinh doanh liên tục.
Tối ưu hóa dung lượng lưu trữ và giảm chi phí với tính năng chống trùng lặp dữ liệu trên Synology
Hiểu được những thách thức về dung lượng lưu trữ và chi phí mà các doanh nghiệp thường gặp phải, Synology đã tiên phong áp dụng công nghệ chống trùng lặp dữ liệu, mang đến giải pháp tối ưu trên thiết bị lưu trữ NAS cho các tổ chức hiện đại. Một vấn đề phổ biến là các doanh nghiệp thường xuyên sao lưu dữ liệu, dẫn đến tình trạng lưu trữ nhiều bản sao trùng lặp trên hệ thống. Điều này gây lãng phí không gian lưu trữ và làm tăng chi phí đầu tư.
Nhằm giải quyết vấn đề này, Synology tích hợp tính năng chống trùng lặp nội tuyến thông minh vào quy trình sao lưu. Khi thực hiện sao lưu, hệ thống sẽ tự động so sánh nội dung dữ liệu mới và loại bỏ các bản sao trùng lặp trước khi ghi vào thiết bị lưu trữ. Nhờ vậy, dung lượng lưu trữ cần thiết được giảm thiểu tối đa, tiết kiệm chi phí hiệu quả.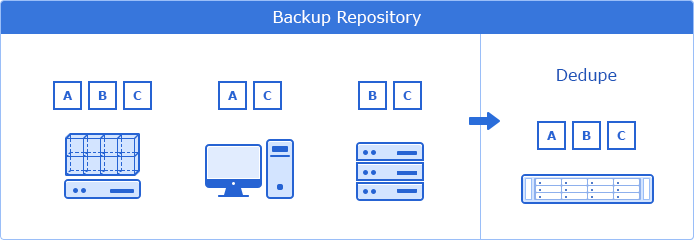
Phương án lưu trữ chống trùng lặp trên Synology
Bên cạnh đó, Synology còn triển khai công nghệ chống trùng lặp toàn diện ở cấp độ khối, cho phép loại bỏ các bản sao trùng lặp giữa nhiều nguồn sao lưu khác nhau. Nhờ vậy, dù thực hiện nhiều tác vụ sao lưu song song trong cùng một thư mục, hệ thống cũng đảm bảo không lưu trữ dữ liệu trùng lặp, tối ưu hóa hiệu quả sử dụng dung lượng lưu trữ.
Tổng kết
Công nghệ chống trùng lặp dữ liệu tiên tiến của Synology đóng vai trò như giải pháp tối ưu, giúp người dùng giải quyết bài toán lưu trữ dữ liệu một cách hiệu quả và tiết kiệm. Nhờ khả năng loại bỏ các bản sao trùng lặp, Synology giúp giảm thiểu đáng kể dung lượng lưu trữ cần thiết, đồng thời tối ưu hóa hiệu suất truy cập dữ liệu. Bên cạnh đó, công nghệ này còn mang đến lợi ích thiết thực trong việc bảo vệ dữ liệu toàn diện. Việc lưu trữ dữ liệu một cách hiệu quả giúp giảm thiểu nguy cơ mất mát dữ liệu do lỗi phần cứng hoặc các sự cố hệ thống. Hy vọng rằng qua bài viết này, bạn đã hiểu rõ hơn về lợi ích của công nghệ chống trùng lặp dữ liệu để áp dụng cho doanh nghiệp của mình. Nếu còn điều gì thắc mắc thì hãy liên hệ ngay với Thietbinas.com để giải đáp nhé!

